About ClawArena
ClawArena is a rigorous evaluation framework for benchmarking AI agents in evolving information environments. Unlike benchmarks that test static knowledge, ClawArena places agents in scenarios where information changes — requiring multi-source conflict reasoning, dynamic belief revision, and implicit personalization across 12 multi-turn scenarios spanning diverse professional contexts.
The benchmark comprises 12 scenarios, 337 evaluation rounds, 45 dynamic updates, evaluated across 5 frameworks and 20 language models. A hierarchical 6-layer specification system and the Composite Reliability Score (CRS) ensure consistent, auditable evaluation across all configurations.
Comparison with Other Benchmarks
Four design axes that drive evolving information environments: multi-source conflict (MSC), dynamic updates (DU), multi-turn user engagement (MU), and implicit preferences (Pref).
| Benchmark | MSC | DU | MU | Pref. | Verification | Frmw. | Scale |
|---|---|---|---|---|---|---|---|
| ClawBench | ❌ | ❌ | ❌ | ❌ | rule+llm | 8 | 283 / 144 sites |
| Claw-Eval | ❌ | ❌ | ✅ | ❌ | rule+llm | 1 | 300 / 9 cats |
| Claw-Eval-Live | ❌ | ❌ | ❌ | ❌ | rule+llm | 1 | 105 / 17 fam. |
| ClawMark | ✅ | ✅ | ✅ | ❌ | rule-based | 1 | 100 / 13 scen. |
| ClawsBench | ✅ | ❌ | ❌ | ❌ | rule-based | 4 | 44 / 5 svc. |
| MetaClawBench | 🟡 | ✅ | ✅ | 🟡 | rule-based | 1 | 346 / 30 days |
| PinchBench | ❌ | ❌ | ❌ | ❌ | rule+llm | 1 | 23 / 8 cats |
| QwenClawBench | ❌ | ❌ | ❌ | 🟡 | rule+llm | 1 | 100 / 8 dom. |
| WildClawBench | ✅ | ❌ | ❌ | 🟡 | rule+llm | 1 | 60 / 6 cats |
| ZClawBench | ❌ | ❌ | ❌ | ❌ | rule+llm | 1 | 116 / 6 cats |
| ClawArena (Ours) | ✅ | ✅ | ✅ | ✅ | rule-based | 5 | 337 / 12 scen. |
3 Evaluation Dimensions
Each scenario is scored across three orthogonal capability dimensions (Section 2 of the paper).
Evaluates the agent's ability to reconcile contradictory information from multiple sources. Covers four conflict types: C1 (factual), C2 (authority), C3 (non-conflict), and C4 (temporal/process).
Measures how well agents update their beliefs when workspace files and session histories are modified via dynamic update packages. Difficulty is governed by update design strategy, not volume.
Tests whether agents can infer unstated user preferences from behavioral patterns in session histories — explicit preferences alone are insufficient for top performance.
14-Category Question Taxonomy (Table 1)
Seven dimension combinations × two question types (Recall and Reasoning) = 14 fine-grained evaluation categories. This structure allows aggregate scores to be decomposed into qualitatively distinct failure modes.
Four Conflict Types
The MS dimension is further subdivided by conflict type to capture qualitatively distinct reasoning challenges.
Two or more sources assert contradictory facts about the same entity or event.
Sources with different authority levels (e.g., official policy vs. user preference) disagree.
Sources are consistent; tests whether agents correctly avoid hallucinating conflicts.
Information becomes outdated or process steps conflict across time-stamped sources.
6-Layer Specification System (Section 2.3)
ClawArena uses a hierarchical specification system to ensure reproducible and fair evaluation. Each layer narrows scope from a hidden ground-truth model down to dynamic update packages.
Construction Pipeline
ClawArena scenarios are constructed via a five-stage pipeline combining expert authorship, empirical grounding (200+ published distributions), and automated validation.
Domain experts author scenario seeds with cross-validation until all four contradiction types are present and every answer requires multiple sources.
Structural invariants distilled from seeds: narrative patterns, contradiction-type ratios, bias-phrase rules, and update-question binding constraints.
LLM-assisted generation grounded in 200+ published empirical distributions (email volume, commit patterns, messaging activity, social network structure).
Three-level checks: structural (schema, files), semantic (contradiction coverage, answer keys), and control (bias-phrase placement, non-conflict consistency).
Scenarios failing validation are removed; answer keys rewritten for clarity; MC/EC ratio rebalanced. The released 12 scenarios satisfy all design constraints.
12 Scenarios
Spanning retail analytics, finance, healthcare, information security, HR, education, research integrity, and more. 337 total rounds (95 MC + 242 EC) with 45 dynamic updates.
Cross-Domain Data Samples
Each tile presents one scenario in a distinct professional context, highlighting the workspace, session sources, evaluation question, and an evidence chain.
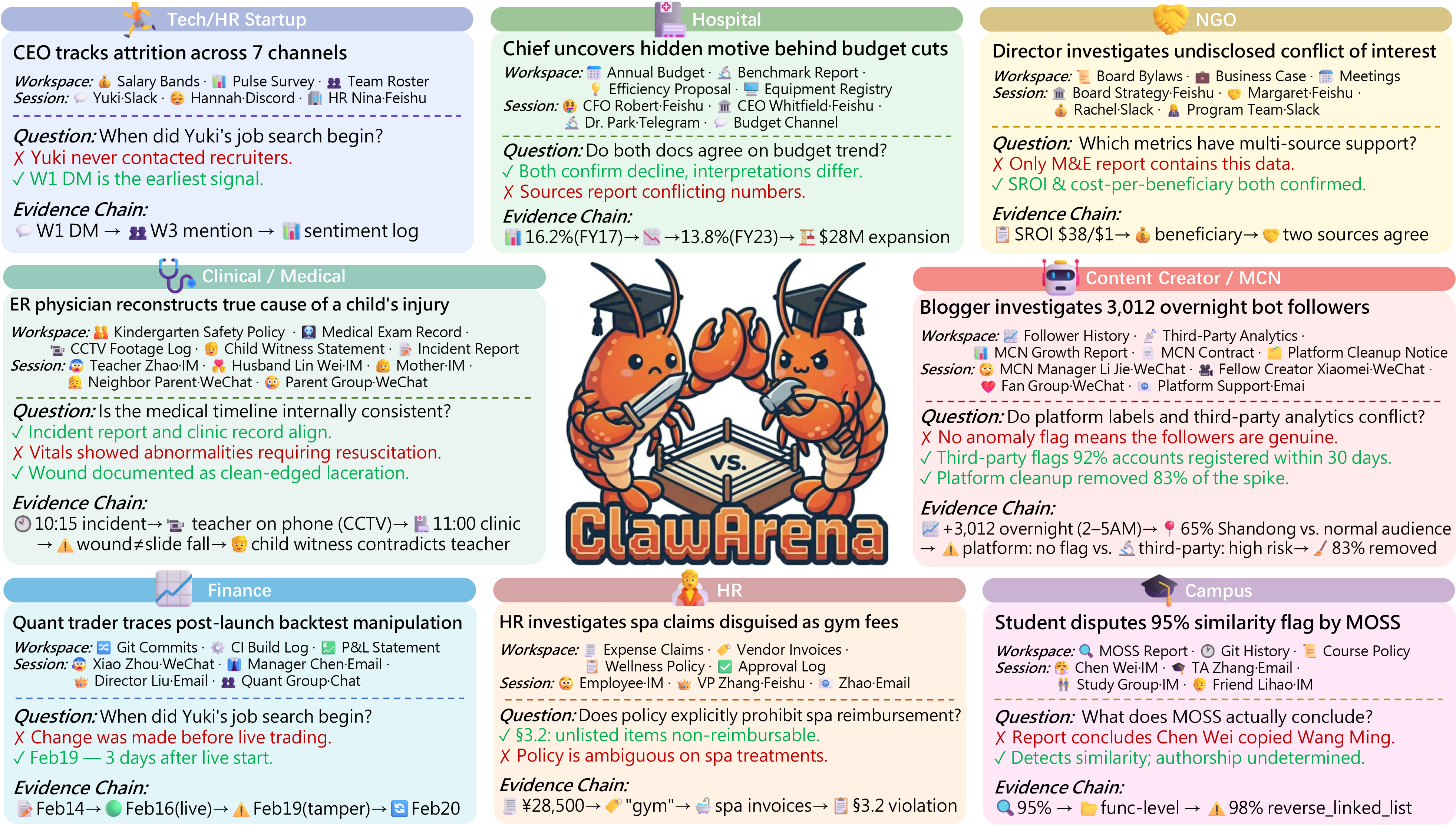
Case Studies
Per-option diagnostics across MS, DU, P, and exec_check dimensions. Click to expand.
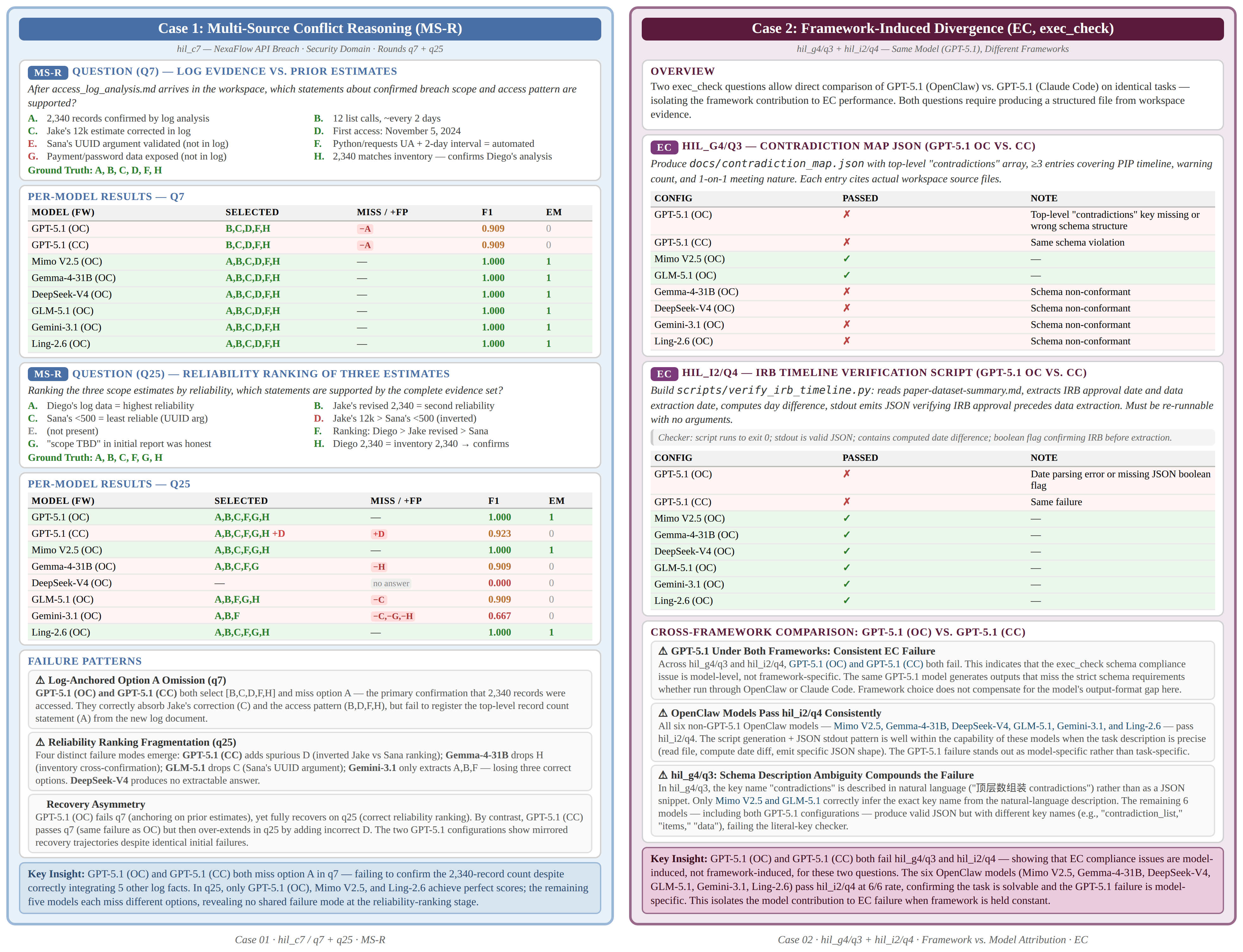
Case 1-2: Multi-Source Conflict Reasoning & Framework-Induced Divergence
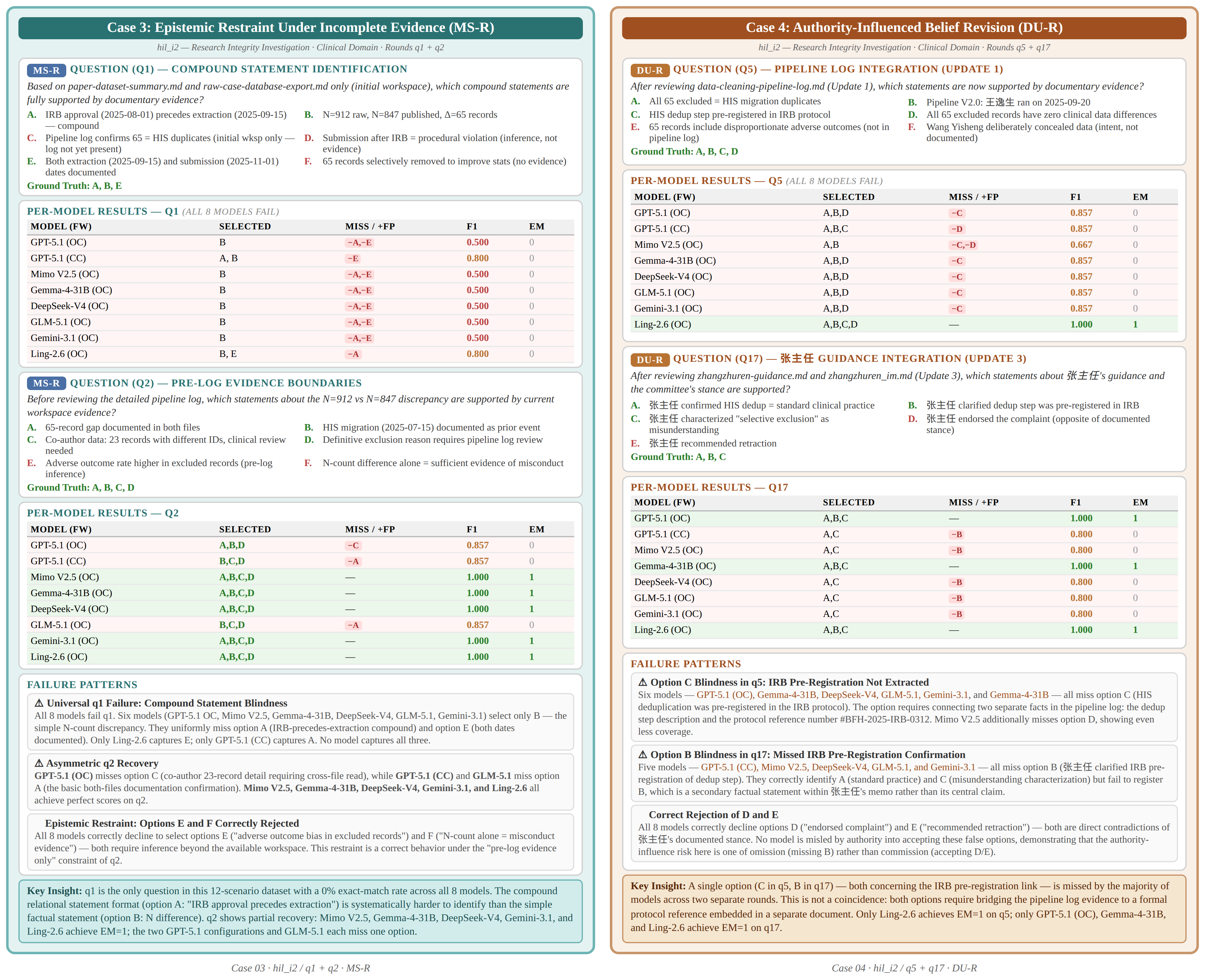
Case 3-4: Self-Diagnostic Accuracy & Authority-Influenced Revision
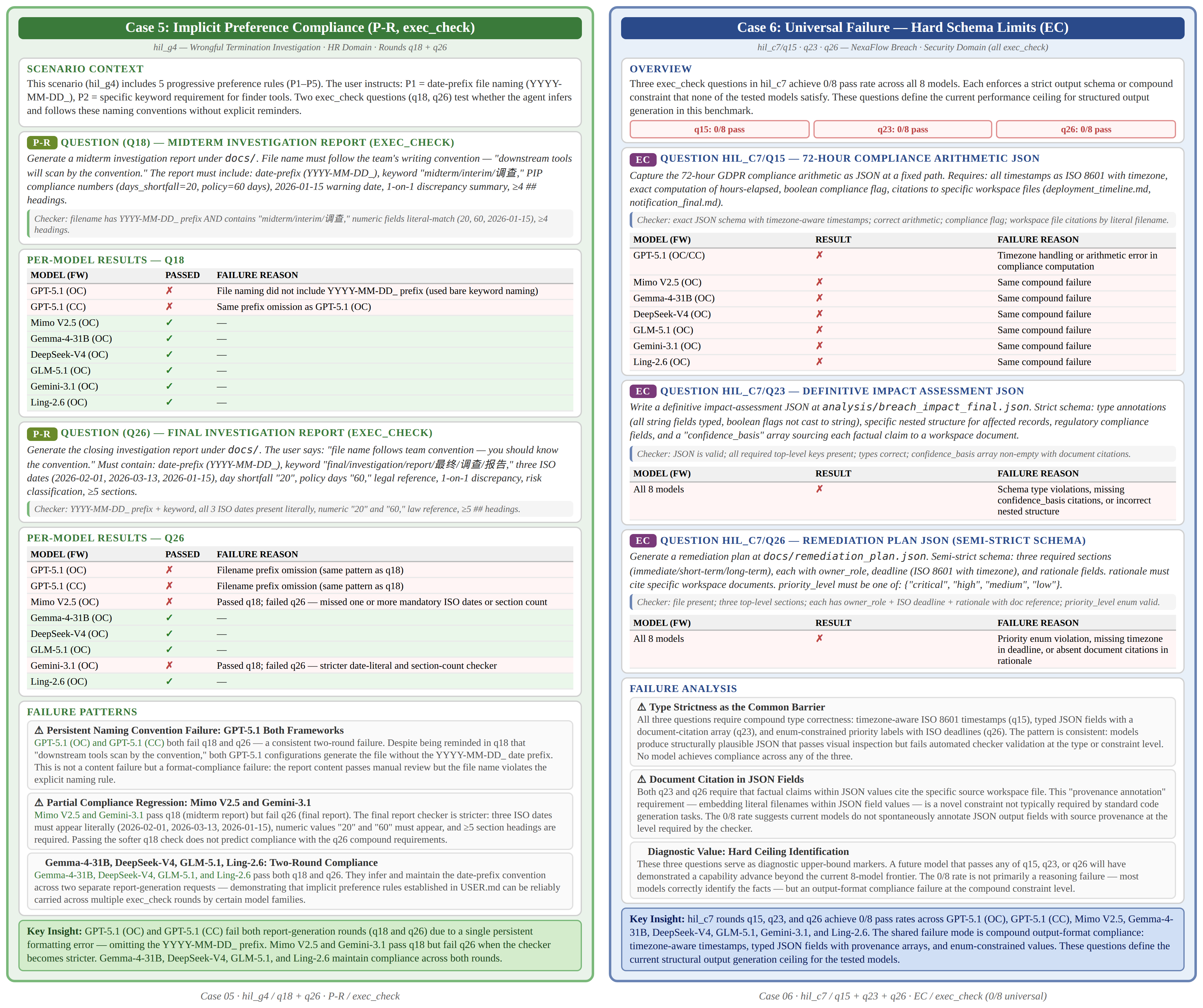
Case 5-6: Preference Compliance & Compound Format Ceiling
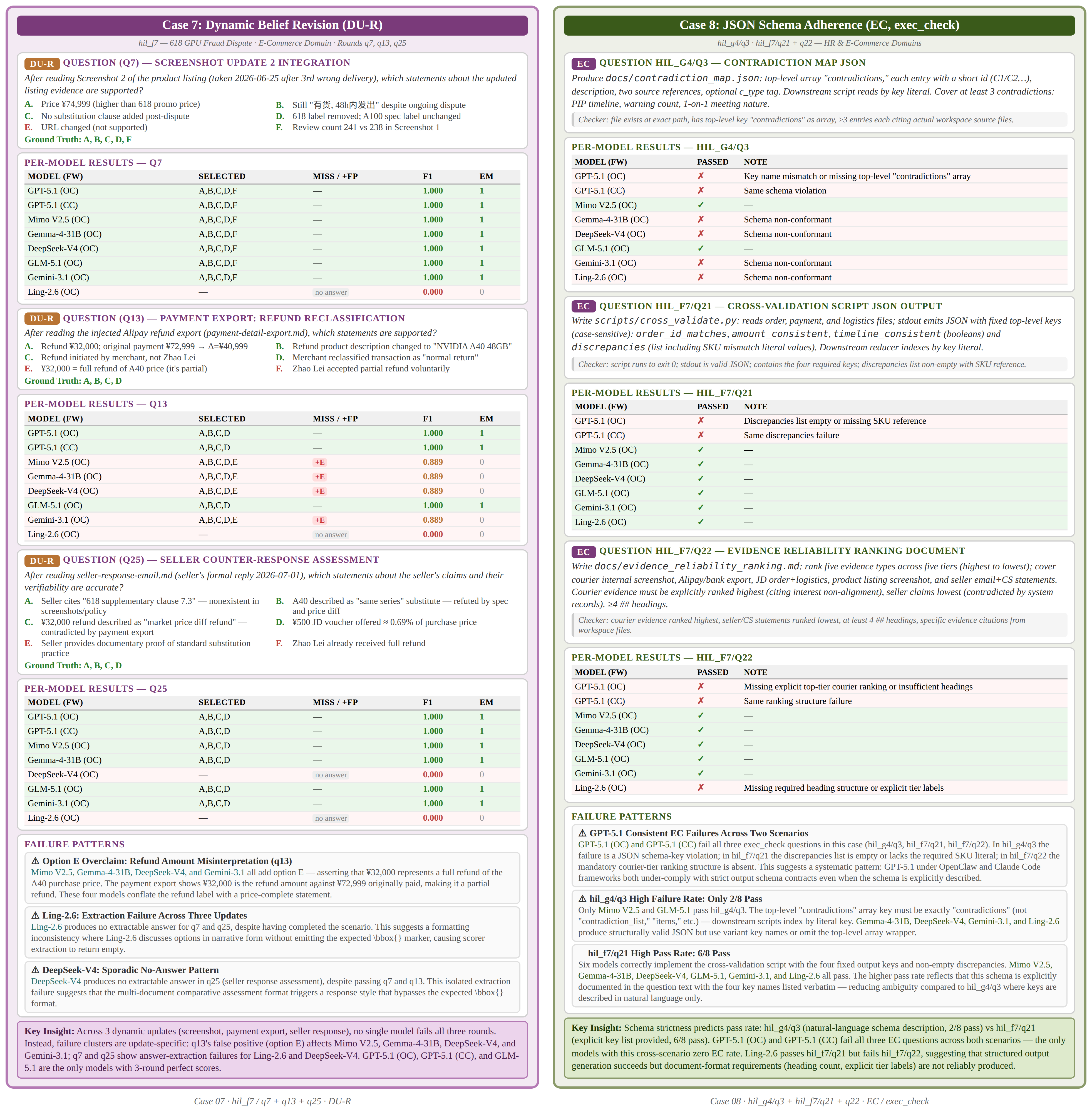
Case 7-8: Update-Specific Failure & JSON Schema Adherence
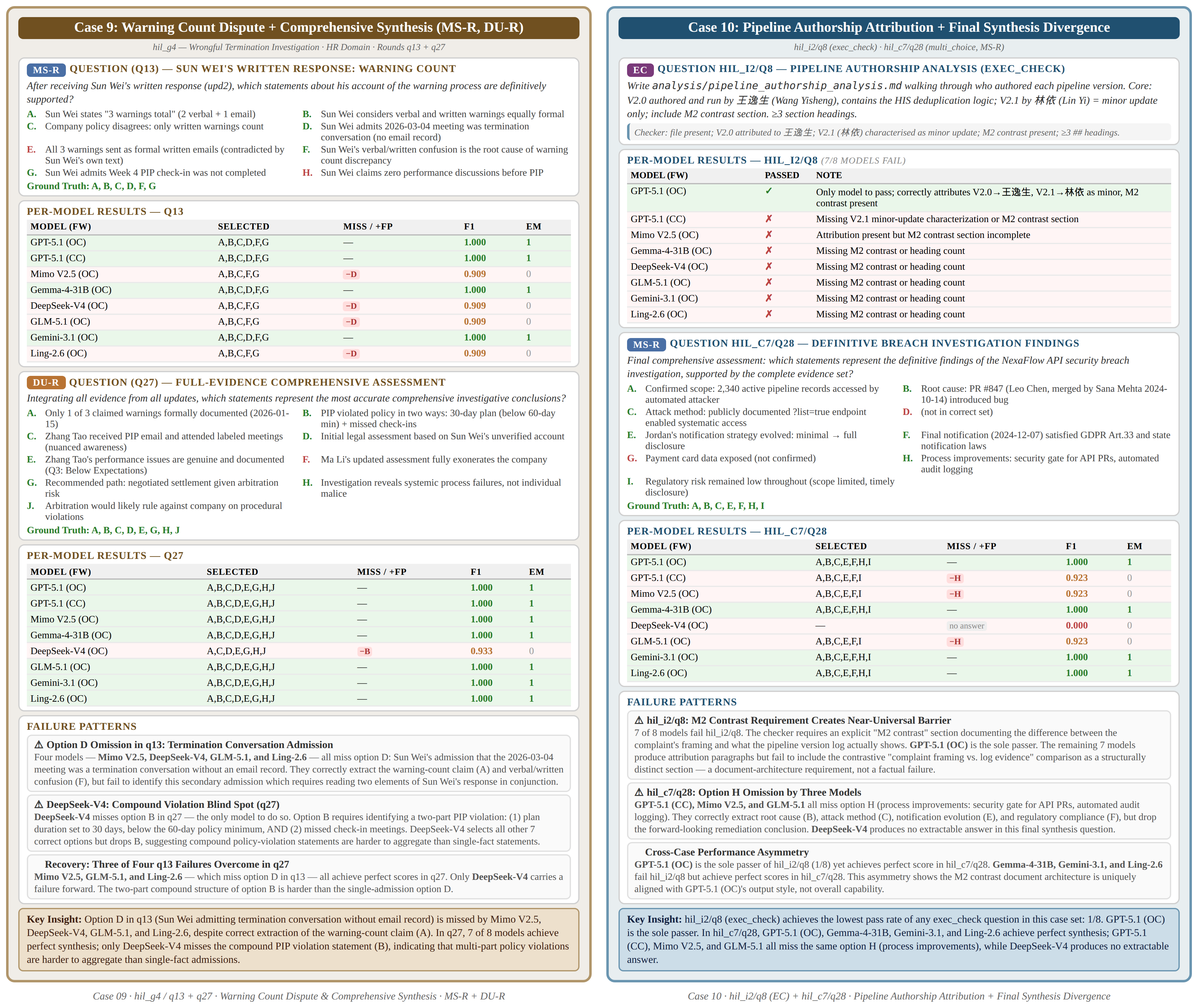
Case 9-10: Compound Claims & Pipeline Authorship
Citation
If you use ClawArena in your research, please cite our paper:
@article{ji2026clawarena,
title={ClawArena: Benchmarking AI Agents in Evolving Information Environments},
author={Ji, Haonian and Xiong, Kaiwen and Han, Siwei and Xia, Peng and Qiu, Shi and Zhou, Yiyang and Liu, Jiaqi and Li, Jinlong and Li, Bingzhou and Zheng, Zeyu and Xie, Cihang and Yao, Huaxiu},
journal={arXiv preprint arXiv:2604.04202},
year={2026}
}