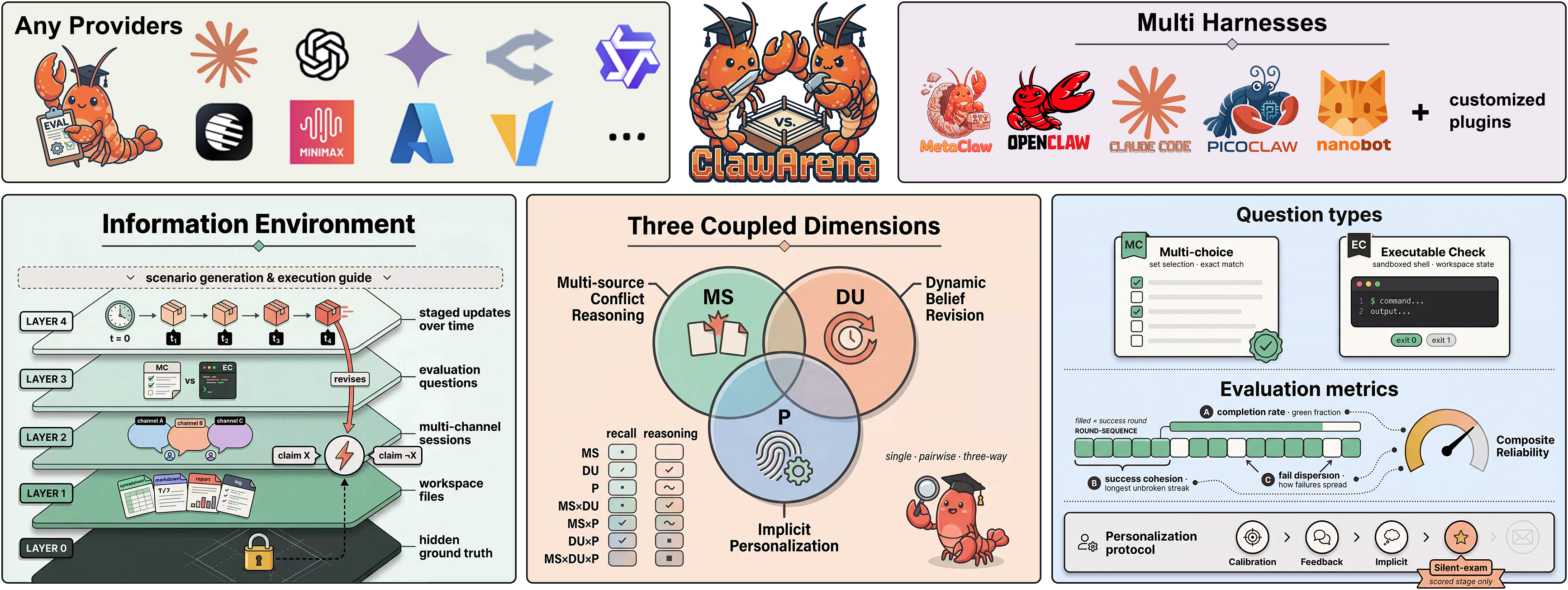
Overview
An evolving information environment with conflicting and progressively updated evidence, structured along three coupled evaluation dimensions.
Leaderboard
All configurations ranked by CRS (Composite Reliability Score) — 20 models × 5 frameworks
What we found
Model capability dominates framework design
Model choice accounts for a 31-point CRS range across 20 models, while framework design accounts for up to 24 points across 4 frameworks. Model capability still dominates, but framework choice is more consequential than previously reported.
MetaClaw improves robustness without degrading accuracy
Skill-based self-evolution consistently improves CRS by 0.33–1.19 across all four tested model families. The mechanism is behavioral consistency (SC and FD both rise), not raw accuracy.
Belief revision difficulty is governed by update design
Updates that force re-interpretation of earlier claims cause clustered failures, while updates that merely extend prior evidence are handled reliably. Update specificity, not volume, determines difficulty.
Three coupled challenges
Real information environments are multi-source, dynamic, and personalized. ClawArena evaluates all three jointly.
14-category taxonomy
7 dimension combinations × 2 types (Recall, Reasoning) prevent systems from scoring well by solving only one dimension.
Executable checks
Shell-based verification of workspace file state. Agents must produce working artifacts, not just text answers.
6-layer specifications
Hidden ground truth (L0) is never shown to agents. Observable layers are noisy, partial reflections of the same underlying reality.
Comparison with agent benchmarks
Four design axes for evolving information environments. ClawArena is the only benchmark satisfying all four simultaneously.
| Benchmark | MSC | DU | MU | Pref. | Verification | Frmw. | Scale |
|---|---|---|---|---|---|---|---|
| ClawBench | ❌ | ❌ | ❌ | ❌ | rule+llm | 8 | 283 / 144 sites |
| Claw-Eval | ❌ | ❌ | ✅ | ❌ | rule+llm | 1 | 300 / 9 cats |
| Claw-Eval-Live | ❌ | ❌ | ❌ | ❌ | rule+llm | 1 | 105 / 17 fam. |
| ClawMark | ✅ | ✅ | ✅ | ❌ | rule-based | 1 | 100 / 13 scen. |
| ClawsBench | ✅ | ❌ | ❌ | ❌ | rule-based | 4 | 44 / 5 svc. |
| MetaClawBench | 🟡 | ✅ | ✅ | 🟡 | rule-based | 1 | 346 / 30 days |
| PinchBench | ❌ | ❌ | ❌ | ❌ | rule+llm | 1 | 23 / 8 cats |
| QwenClawBench | ❌ | ❌ | ❌ | 🟡 | rule+llm | 1 | 100 / 8 dom. |
| WildClawBench | ✅ | ❌ | ❌ | 🟡 | rule+llm | 1 | 60 / 6 cats |
| ZClawBench | ❌ | ❌ | ❌ | ❌ | rule+llm | 1 | 116 / 6 cats |
| ClawArena (Ours) | ✅ | ✅ | ✅ | ✅ | rule-based | 5 | 337 / 12 scen. |